


Si estás leyendo esto es que algo has oído hablar sobre el archivo robots.txt, pero antes de entrar en materia es importante que entendamos a quién va destinado este archivo. Su función principal es facilitar el trabajo a los buscadores, indicando en qué páginas de la web no deben perder el tiempo en visitar.
Los motores de búsqueda buscan y organizan el contenido de las webs con el objetivo que mostrar el contenido más relevante en la página de resultados (SERPs) para el usuario ante una determinada búsqueda. Para realizar esta clasificación, los buscadores realizan tres funciones:
- Rastreo o crawling: los bots, también llamados crawlers o arañas, exploran el contenido de diferentes páginas web y descubren nuevas páginas a través del enlazado. Pero ¡ojo! para que una web sea rastreada, debe ser accesible. Y aquí es donde entra en juego robots.txt, como podrás ver más adelante.
- Indexación: el contenido rastreado se almacena, organiza y cobra sentido al analizarse. En este punto, los buscadores determinan la relevancia o no de la página para mostrarse en los resultados de búsqueda, entrando en juego factores como la autoridad o las etiquetas de control de indexación como <meta name=»robots» content=»noindex»> o <link rel=”canonical” href=”url”>.
- Clasificación: los buscadores ponderarán los contenidos y los ordenará en los resultados de búsqueda.
Contenidos
¿Qué es robot.txt?
El robots.txt es un archivo en el que se proporcionan unas serie de instrucciones sobre las páginas que no queremos que el bot rastree -y, por tanto, no indexe-, además de otros parámetros como la ubicación del sitemap.xml, que es el índice de las páginas de la web.
Para qué sirve robots.txt
Cuando un bot llega a un sitio web, en principio, lo primero que busca es el robots.txt. Si tenemos un robots.txt bien configurado, le facilitaremos la tarea a los buscadores. Estas son las cosas que puedes definir en el robots.txt:
- Bloqueo de partes de nuestra web que no queremos que el crawler rastree ni indexe porque no son relevantes. De esta manera, los bots no perderán presupuesto de rastreo (crawl budget) en rastrear páginas de nuestro sitio web que no nos interes indexar, sino que centrarán los esfuerzos en las páginas más relevantes para nosotros.
- Bloqueo de web en desarrollo. Hasta ahora, era común también el uso de directivas en el robots.txt para bloquear el rastreo de indexación de una web en construcción que está en la red, ya sea mediante el bloqueo completo del dominio o mediante el bloqueo de carpetas en las que se encuentre la nueva web (cuando tenemos una web publicada y alojamos otra en el mismo dominio).
- Bloqueo de partes internas de la web. Puede ser que en nuestra web tengamos páginas de gestión interna a la que solamente acceden nuestros empleados o, en el caso de un ecommerce, nuestros clientes mediante logueo. En el caso de WordPress, además, existe un directorio dedicado a la administración del sitio, WP-ADMIN, que no tiene sentido que el crawler rastree.
- Dirección del sitemap.xml. Como hemos dicho anteriormente, el sitemap.xml es el índice de las páginas de nuestra web, por lo que es útil que le indiquemos al bot la ubicación en la que puede encontrarlo en el primer archivo que rastrea cuando entra a nuestro sitio web. Pero ¡ojo! recuerda tener también configurar el sitemap.xml correctamente.
- Bloqueo de ciertos bots. En el robots.txt se puede establecer bloqueos por tipo de bot. De esta manera, podemos definir qué bot no queremos que rastree determinadas páginas o, lo más común, bloquear el rastreo del sitio completo. Esto es utilizado para no desperdiciar recursos en bot que no nos interesan o para evitar el rastreo de herramientas de marketing que pueda utilizar la competencia para analizar nuestro sitio web. Pero hay que tener en cuenta que no todos los bots respetan las directivas del robots.txt.
¿Cómo generar un robots.txt en WordPress?
Cuando instalamos un WordPress, se genera automáticamente un archivo robots.txt, ubicado en la carpeta raíz del sitio web, y al que podrás acceder poniendo en el navegador: “tudominio.com/robots.txt”. Si no has configurado parámetros adicionales, encontrarás un archivo como el siguiente:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
En versiones anteriores de WordPress, cuando activabas la casilla “Disuade a los motores de búsqueda de indexar este sitio”, pensada para evitar la indexación de contenido mientras la web estaba en fase de desarrollo. Al marcar la casilla, WordPress creaba un robots.txt como el siguiente:
User-agent: *
Disallow: /
Esta regla lo que hace es bloquear el acceso a todos los bots a todo el sitio web. Sin embargo, la versión WordPress 5.3 cambia la forma de indicar a los motores de búsqueda que eviten el indexado del sitio web. En lugar de poner una directiva en el robots.txt, en los sitios con la opción “Disuade a los motores de búsqueda de indexar este sitio” activada se generará la metaetiqueta <meta name=’robots’ content=’noindex,nofollow’ />.
Esto se debe a que, aunque lo más común es que de la indexación se pase a la clasificación, lo cierto es que una página bloqueada por robots.txt puede ser mostrada en los resultados de búsqueda por ejemplo, si se encuentran enlaces apuntando a ella. En palabras de Joost de Valk, fundador de Yoast SEO:
“No es necesario rastrear un sitio para que aparezca en la lista. Si un enlace apunta a una página, dominio o donde sea, Google sigue este enlace. Si el archivo robots.txt en ese dominio impide que un motor de búsqueda rastree esa página, seguirá mostrando la URL en los resultados”
Por ello, si lo que se desea es evitar la indexación de la página, lo ideal es meter una etiqueta <meta name=»robots» content=»noindex,nofollow»> en la cabecera del contenido que no queremos indexar, ya que Google lo leerá al rastrear ese contenido.
Reglas de robots.txt
El robots.txt, tanto en WordPress como en el resto de CMS, se construye determinando, por un lado, el bot al que van destinadas las reglas y, por otro, las que reglas que ha de seguir el bot. Estos son los parámetros utilizados:
- User Agent: especifica para qué bots están destinadas las reglas que se pongan a continuación.
- Disallow: es la regla que especifica el bloqueo de acceso. Tras “Disallow: “ se pondrá la ruta que queremos bloquear.
- Allow: es la regla que realiza excepciones a disallow. Es decir, añade rutas a las que el bot si podrá entrar aunque estén dentro de las carpetas excluidas anteriormente. Tras “Allow: “ se pondrá la ruta que queremos desbloquear.
- Crawl-delay: determina el tiempo entre peticiones que el bot hace en el sitio web; sin embargo, su efectividad es casi nula, ya que bots como Googlebot no toman en cuenta esta directiva.
- Sitemap: especifica la ruta en el que se encuentra el sitemap del sitio web.
Además, existen parámetros comodines que te ayudarán a configurar tu robots.txt:
- Asterisco (*): es un comodín que se utiliza para incluir “todos”. Por ejemplo:
- User-agent: * > Estamos indicando que las reglas se aplicarán a todos los bots.
- Disallow: / > Estamos indicando que estarán bloqueados todos los directorios.
- Dólar ($): se utiliza en las extensiones para indicar que la regla se aplica a todos los archivos que acaben en una extensión concreta. Por ejemplo:
- /*.html$ > Estamos indicando que la regla será aplicada a todos los archivos html.
Si no se especifica nada en el robots.txt se entiende que se le está permitiendo el paso al robot por toda tu web.
Reglas del robots.txt para WordPress
Además de las reglas concretas que requiera la web, existen algunas reglas comunes que suelen usarse en WordPress:
#Bloqueo básico
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /xmlrpc.php
Con estas reglas estamos bloqueando recursos del CMS no relacionados directamente con el contenido (que estará en la carpeta wp-content). Sin embargo, el bloqueo de /wp-includes/ puede dar problemas en GSC debido al bloqueo de recursos. Para permitir que Google rastree CSS y JavaScript, que también gestionan y muestran el contenido, se debe añadir “allow” a estos recursos:
Allow: /wp-includes/*.js
Allow: /wp-includes/*.css
Editar robots.txt de WordPress de manera manual
Como hemos visto, WordPress crea automáticamente un robots.txt en tu sitio web, pero ahora que sabes más sobre este archivo, posiblemente quieras crear uno a medida de tu web.
Generalmente, este archivo se encuentra en la carpeta raiz del dominio, que encontrarás en tu FTP como www o public_html. Para editar este robots.txt, solo deberás crear uno a tu medida desde cero y subirlo a la carpeta raíz de tu web a través del FTP para reemplazar el anterior.

Editar robots.txt en wordpress con plugin
Aunque es muy sencillo editar el archivo robots.txt de manera manual, si no quieres tocar las tripas de tu web, puedes hacerlo utilizando un plugin. Existen una infinidad de plugins que editan el robots.txt. Aquí te dejamos algunos de los más utilizados:
-
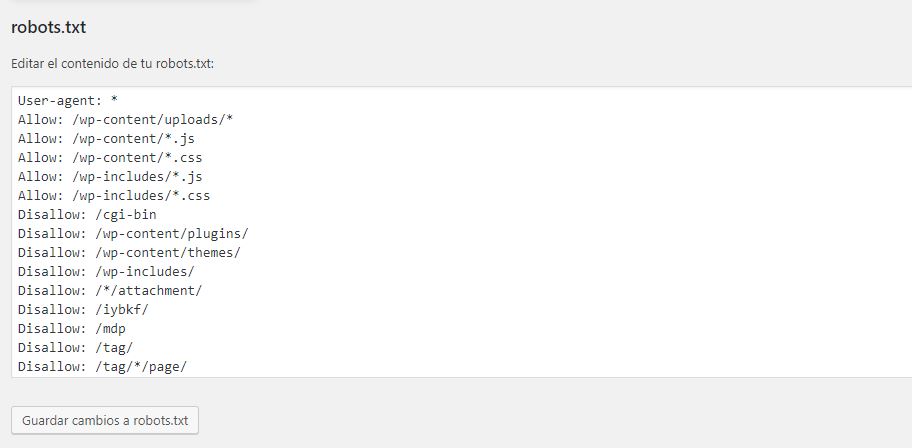
Robots.txt en Yoast SEO
Si estás metido en el mundo SEO en WordPress, seguramente ya conozcas este plugin. Se trata del plugin de SEO más utilizado debido, entre otras cosas, a su facilidad de uso. Para acceder al robots.txt, ve a la pestaña SEO > Herramientas > Editor de archivos (si no te aparece esta opción, revisa que tengas todos los permisos en el plugin). Al pulsar en “Crear robots.txt”, accederás al editor del robots sin salir de tu escritorio. Una vez que hayas metido las reglas que quieras, pulsa “Guardar cambios en robots.txt” y ¡voilà! este robots anulará las reglas que tengas en el robots.txt de tu carpeta raíz.
-
Robots.txt en All in One SEO
Es otro de los plugins SEO más populares que, como no podía ser de otra manera, también incluye la opción de editar el robots.txt desde la interfaz de WordPress. Y más sencillo si cabe que con Yoast SEO. Podrás hacerlo entrando en “Gestor de utilidades” del menú izquierdo > Robots.txt.
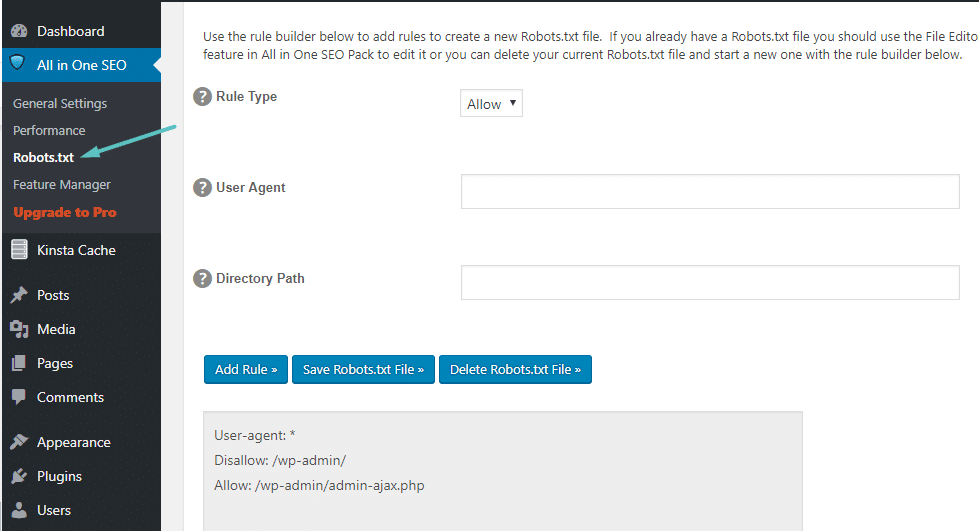
Únicamente tendrás que seleccionar el tipo de regla, poner el bot al que se destina y la ruta que quieres bloquear o desbloquear. Además, este plugin te permite bloquear directamente bots maliciosos. Sencillo ¿no?
Probar robots.txt
Como hemos comentado anteriormente, para ver el robots.txt solo tienes que acceder a tudomino.com/robots.txt. Pero si además de verlo quieres testearlo, puedes hacerlo entrando en: https://www.google.com/webmasters/tools/robots-testing-tool. Se trata de una herramienta integrada en Google Search Console,por lo que tendrás que tener una cuenta y la propiedad en GSC.
Una vez logueado, elige la propiedad y te aparecerá el sitemap.xml del sitio web en cuestión. Pero lo más útil de esta herramienta es la posibilidad de saber si una URL concreta está bloqueada por los parámetros que metemos en el robots.txt, lo que resulta muy útil cuando estamos usando parámetros generales o muchas reglas.

Conclusión
Si lo que buscas es aumentar el posicionamiento y visibilidad de tu web, debes asegurarte de que los bots, y muy especialmente Googlebot, rastree el contenido que más te interesa mostrar de tu web. Y el robots.txt puede ayudarte. Eso sí, asegúrate de configurarlo correctamente. Y recuerda:
1)Que incluyas una carpeta en tu archivo robots.txt no significa que Google no vaya a indexarlo. Si Google encuentra enlaces externos a una determinada aunque tú estés bloqueándola en el robots.txt puede indexarse. Si quieres evitar que una URL de verdad se indexe te recomentamos la meta etiqueta «no index».
2) Siempre recomendamos tener robots.txt. Aunque pienses que quieres darle acceso a todos los motores de búsqueda a tu sitio, siempre recomendamos tener este archivo.
3) Introduce el sitemap al final del robots.txt: es una buena práctica que ayudará a mejorar la indexación de tu sitio (sitemap: tudominio.com/sitemap.xml).
4) Puedes testear tu robots.txt en Webmaster Tools.
5) Si pones disallow a una carpeta, todo lo que hay dentro de esa carpeta, subcarpetas y archivos estará siendo bloqueado.
Si necesitas ayuda en esto o quieres aumentar el posicionamiento de tu página web, no lo dudes: ¡ponte en contacto con nosotros!

0 comentarios